1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
| import * as tf from '@tensorflow/tfjs';
import * as tfvis from '@tensorflow/tfjs-vis';
import { MnistData } from './data';
window.onload = async () => {
const data = new MnistData();
await data.load();
const examples = data.nextTestBatch(20);
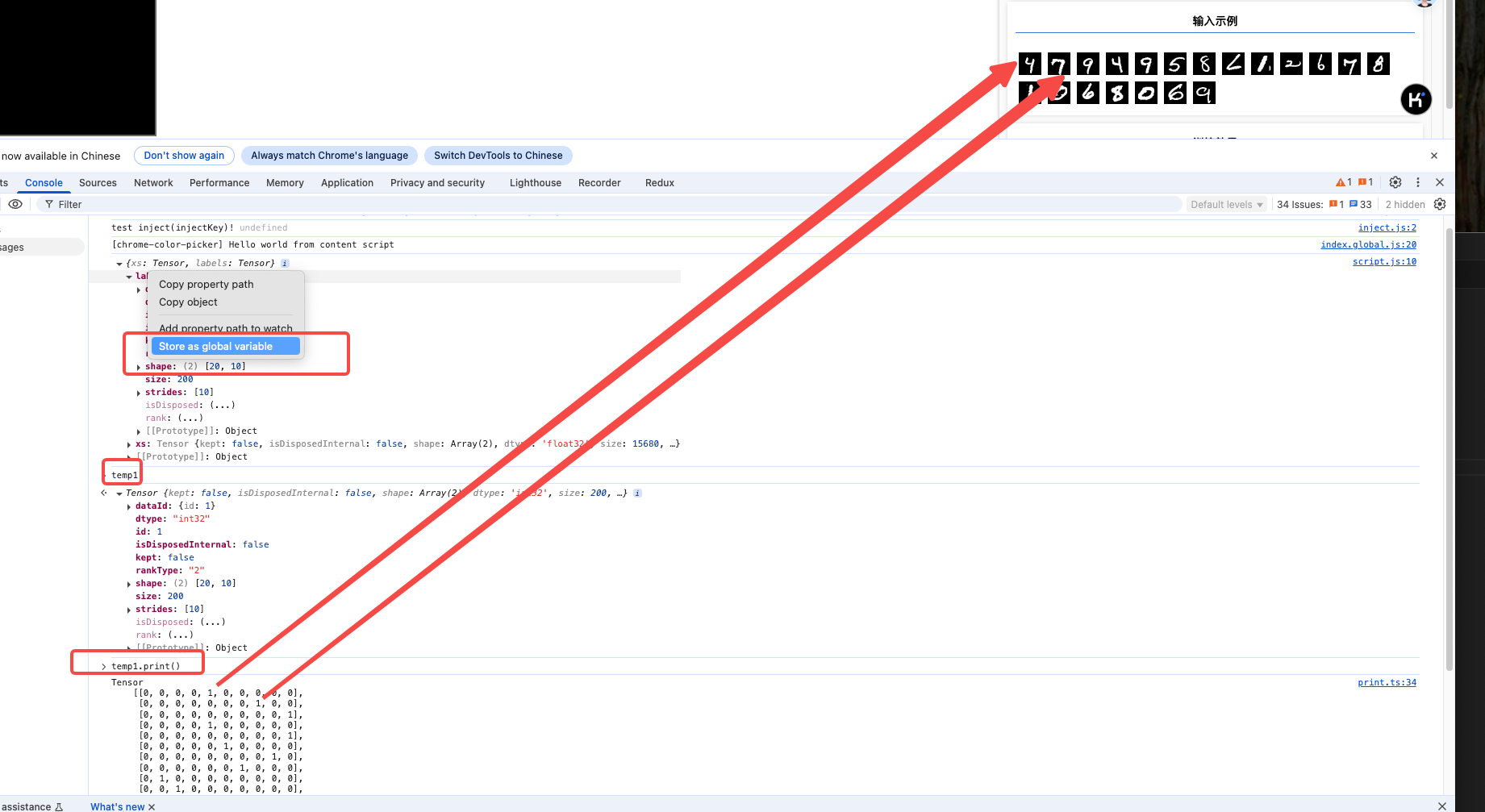
console.log(examples)
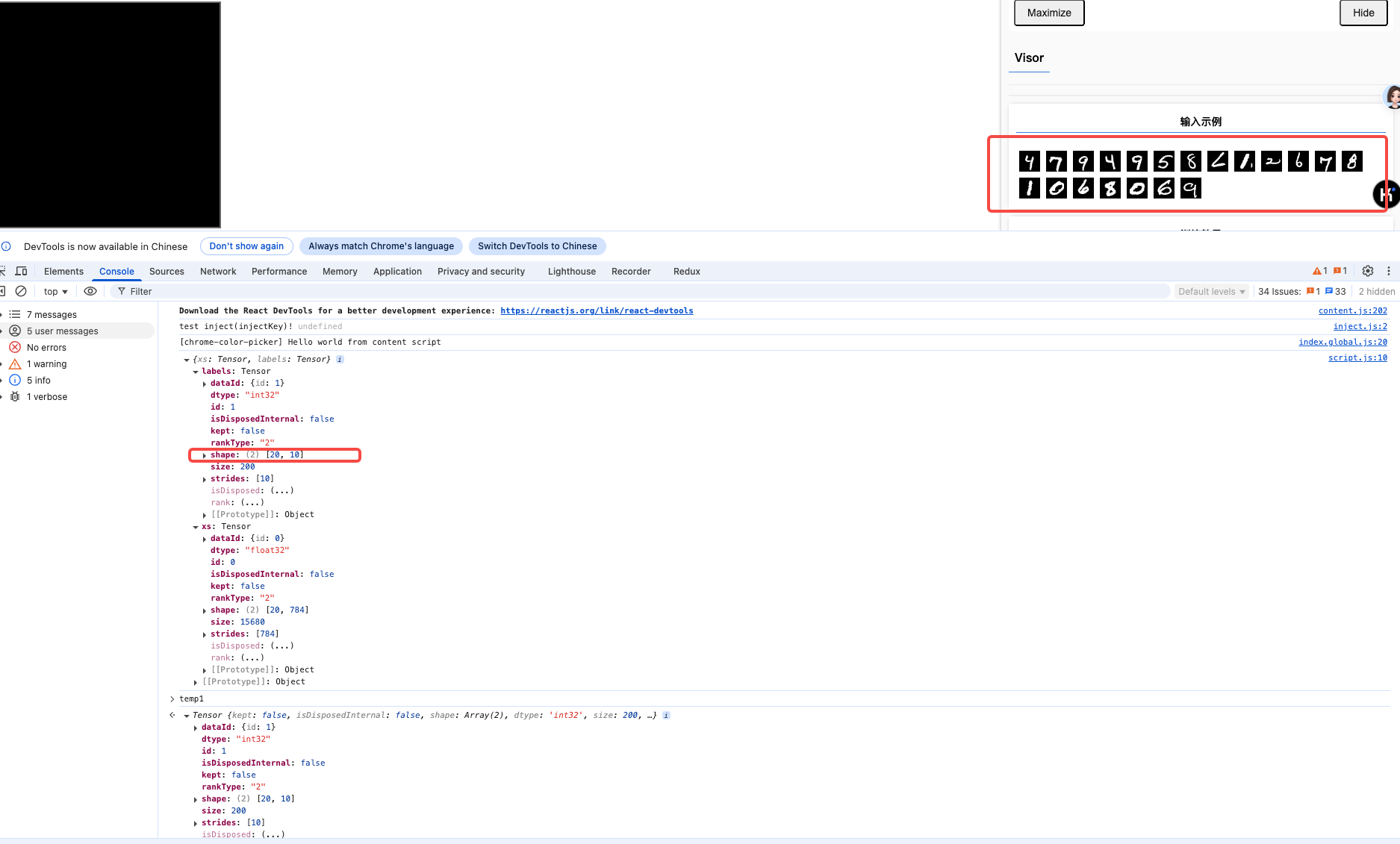
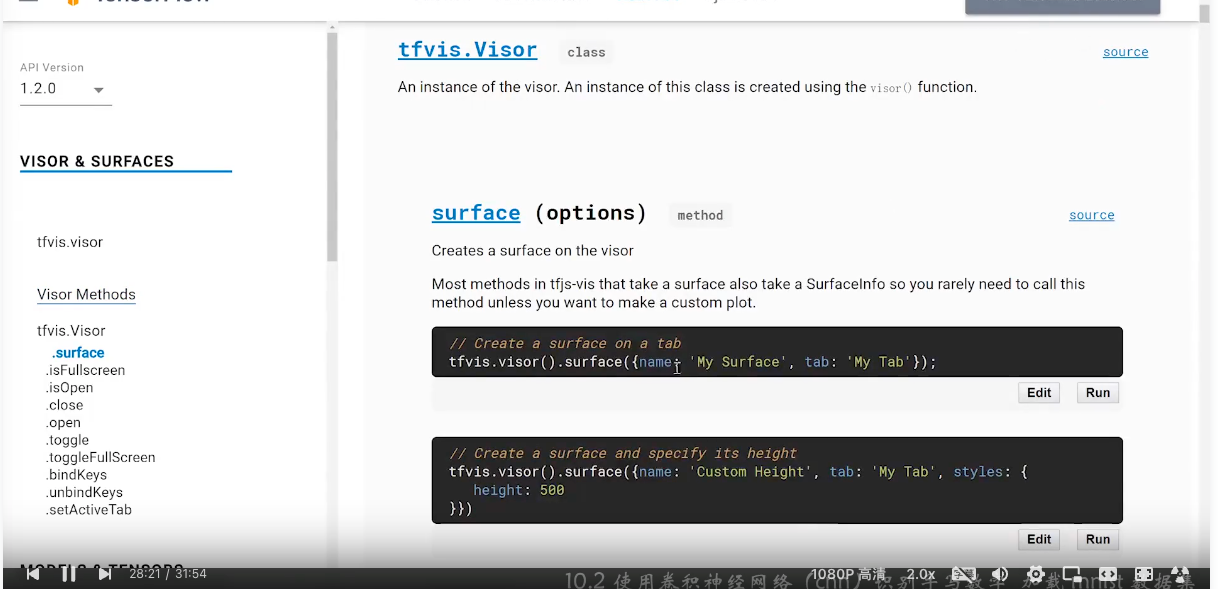
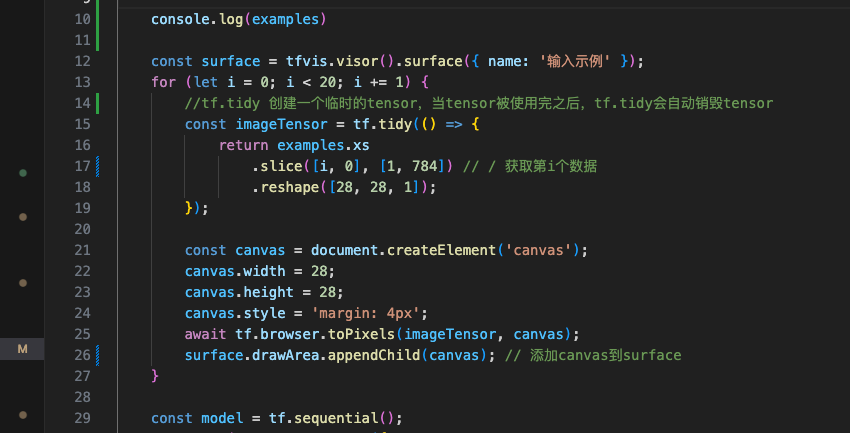
const surface = tfvis.visor().surface({ name: '输入示例' });
for (let i = 0; i < 20; i += 1) {
//tf.tidy 创建一个临时的tensor,当tensor被使用完之后,tf.tidy会自动销毁tensor
const imageTensor = tf.tidy(() => {
return examples.xs
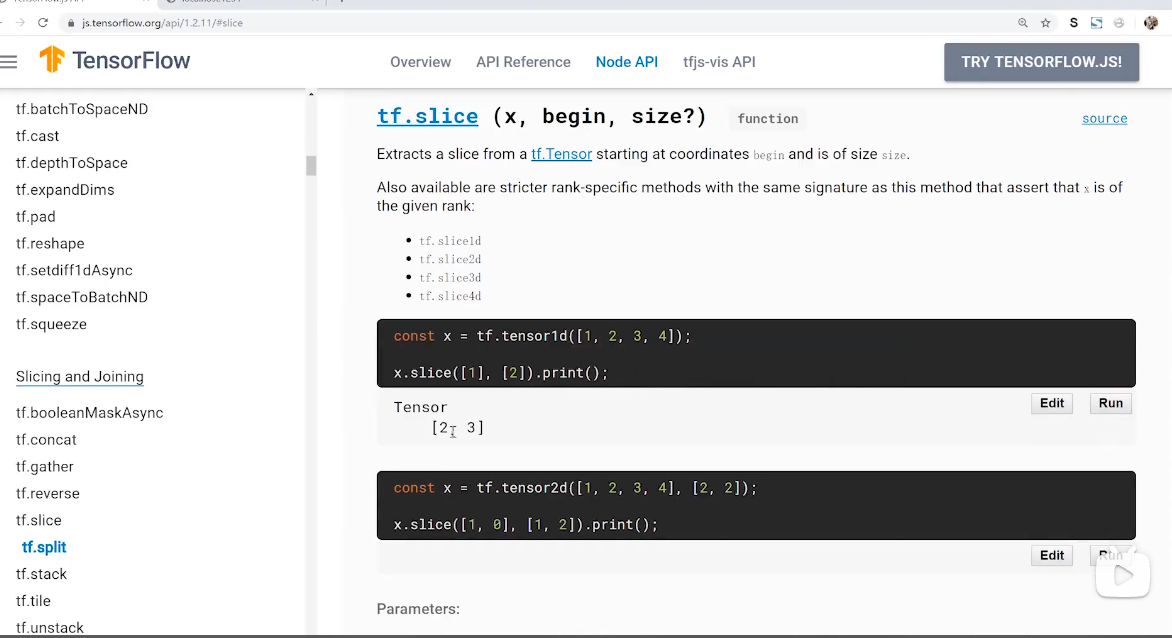
.slice([i, 0], [1, 784]) // / 获取第i个数据
.reshape([28, 28, 1]);
});
const canvas = document.createElement('canvas');
canvas.width = 28;
canvas.height = 28;
canvas.style = 'margin: 4px';
await tf.browser.toPixels(imageTensor, canvas); // 将tensor转为canvas
surface.drawArea.appendChild(canvas); // 添加canvas到surface
}
const model = tf.sequential();
model.add(tf.layers.conv2d({
inputShape: [28, 28, 1],
kernelSize: 5, // 卷积核大小,奇数有中心点
filters: 8, // 卷积核数量,即输出通道数量
strides: 1, // 步长,即卷积核滑动的步长
activation: 'relu',
kernelInitializer: 'varianceScaling' // 初始化权重的函数,这里使用varianceScaling,即权重初始化为0,方差为1
}));
// 池化层,将输入的图片缩小,即缩小图片的分辨率,但图片内容不变
model.add(tf.layers.maxPool2d({
poolSize: [2, 2], // 池化核大小
strides: [2, 2] // 滑动步长
}));
model.add(tf.layers.conv2d({
kernelSize: 5,
filters: 16,
strides: 1,
activation: 'relu',
kernelInitializer: 'varianceScaling'
}));
model.add(tf.layers.maxPool2d({
poolSize: [2, 2],
strides: [2, 2]
}));
model.add(tf.layers.flatten()); // 展平,将二维数组变为一维数组
model.add(tf.layers.dropout({ rate: 0.9 })); // 防止过拟合,随机丢弃一些神经元
model.add(tf.layers.dense({
units: 10, // 0-9 10个分类
activation: 'softmax', // 输出为0-9的概率
kernelInitializer: 'varianceScaling' // 权重初始化为0,方差为1
}));
model.compile({
loss: 'categoricalCrossentropy', // 交叉熵损失函数,用于多分类
optimizer: tf.train.adam(), // Adam优化器,用于训练
metrics: ['accuracy'] // 准确率
});
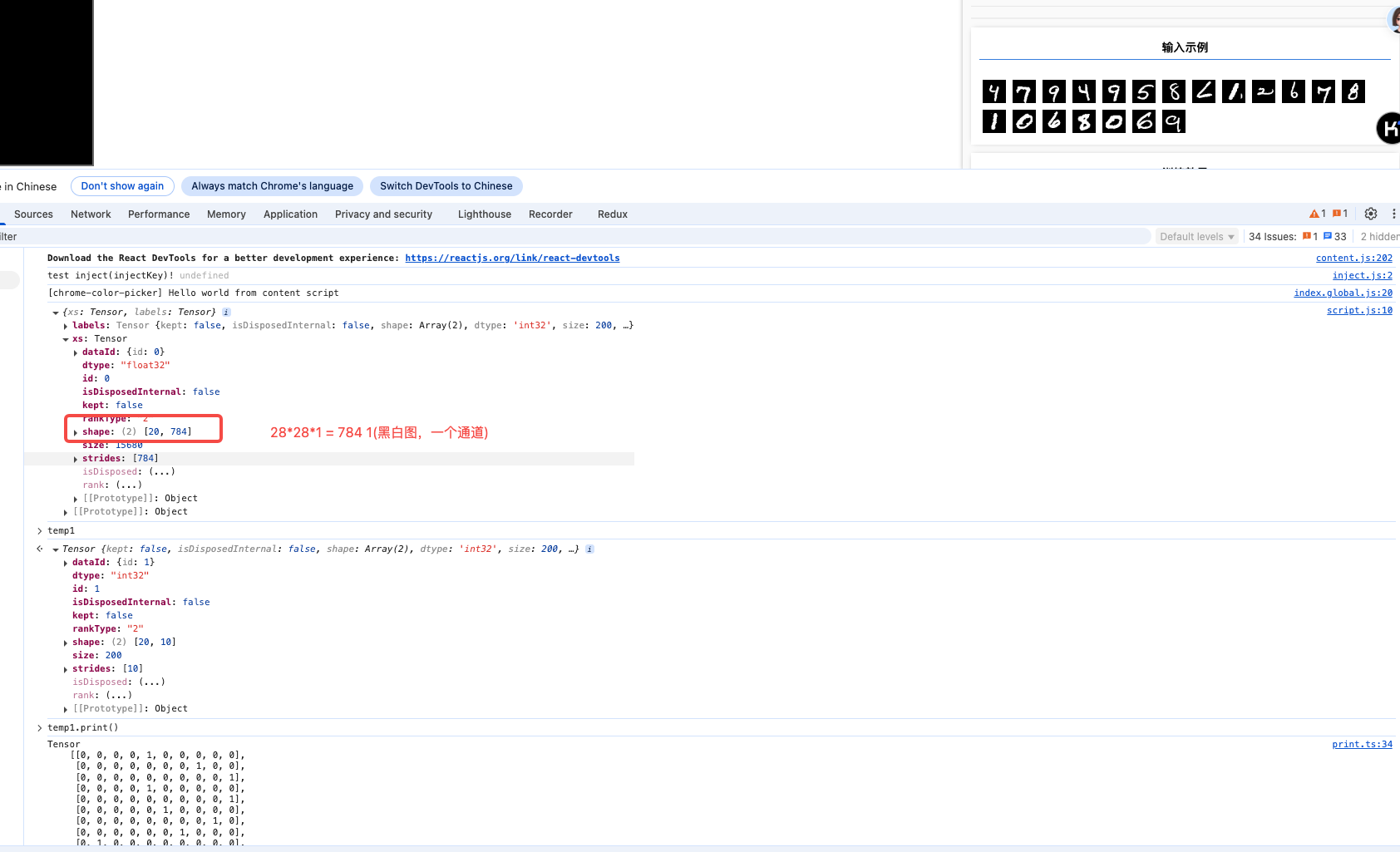
const [trainXs, trainYs] = tf.tidy(() => {
const d = data.nextTrainBatch(1000); // 获取训练数据 1000个训练数据
console.log(d)
return [
d.xs.reshape([1000, 28, 28, 1]),
d.labels
];
});
const [testXs, testYs] = tf.tidy(() => {
const d = data.nextTestBatch(200); // 获取测试数据
return [
d.xs.reshape([200, 28, 28, 1]),
d.labels
];
});
await model.fit(trainXs, trainYs, {
validationData: [testXs, testYs],
batchSize: 50,
epochs: 100,
callbacks: tfvis.show.fitCallbacks(
{ name: '训练效果' },
['loss', 'val_loss', 'acc', 'val_acc'],
{ callbacks: ['onEpochEnd'] }
)
});
const canvas = document.querySelector('canvas');
canvas.addEventListener('mousemove', (e) => {
if (e.buttons === 1) { // 左键按下
const ctx = canvas.getContext('2d');
ctx.fillStyle = 'rgb(255,255,255)'; // 白色
ctx.fillRect(e.offsetX, e.offsetY, 25, 25); // 画一个25*25的矩形
}
});
window.clear = () => {
const ctx = canvas.getContext('2d');
ctx.fillStyle = 'rgb(0,0,0)'; // 黑色
ctx.fillRect(0, 0, 300, 300); // 填充一个黑色
};
clear();
window.predict = () => {
const input = tf.tidy(() => {
return tf.image.resizeBilinear( // 缩放图片
tf.browser.fromPixels(canvas), // 缩放图片
[28, 28], // 缩放后的大小
true // 是否保持图片的宽高比
).slice([0, 0, 0], [28, 28, 1]) // 将彩色图片转换为黑白图片 获取图片的像素
.toFloat() // 转换为浮点数
.div(255) // 转换为0-1
.reshape([1, 28, 28, 1]); // 转换为张量
});
const pred = model.predict(input).argMax(1);
alert(`预测结果为 ${pred.dataSync()[0]}`);
};
};
|