Predicts only two boxes per grid cell (same class)
• Poor performance with small, clustered objects.
• Struggles with multiple categories per grid cell.
• Issues with unusual object aspect ratios.
• Lower accuracy compared to other methods.
每个网格单元仅预测两个盒子(同一类)
•小的聚集物对象的性能差。
•每个网格单元格与多个类别的斗争。
•与异常对象宽高比的问题。
•与其他方法相比,精度较低。
•最多预测49个分类


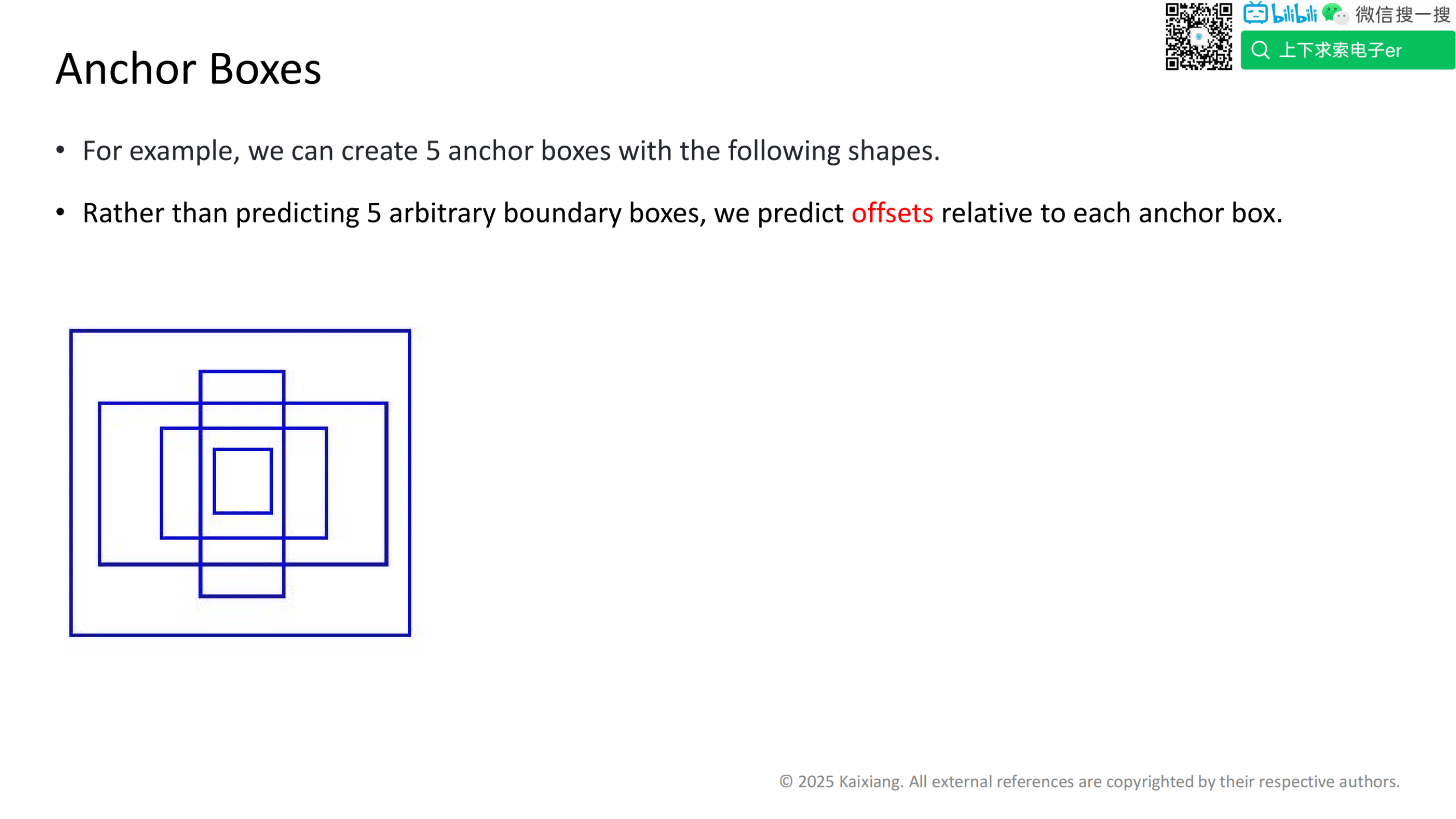
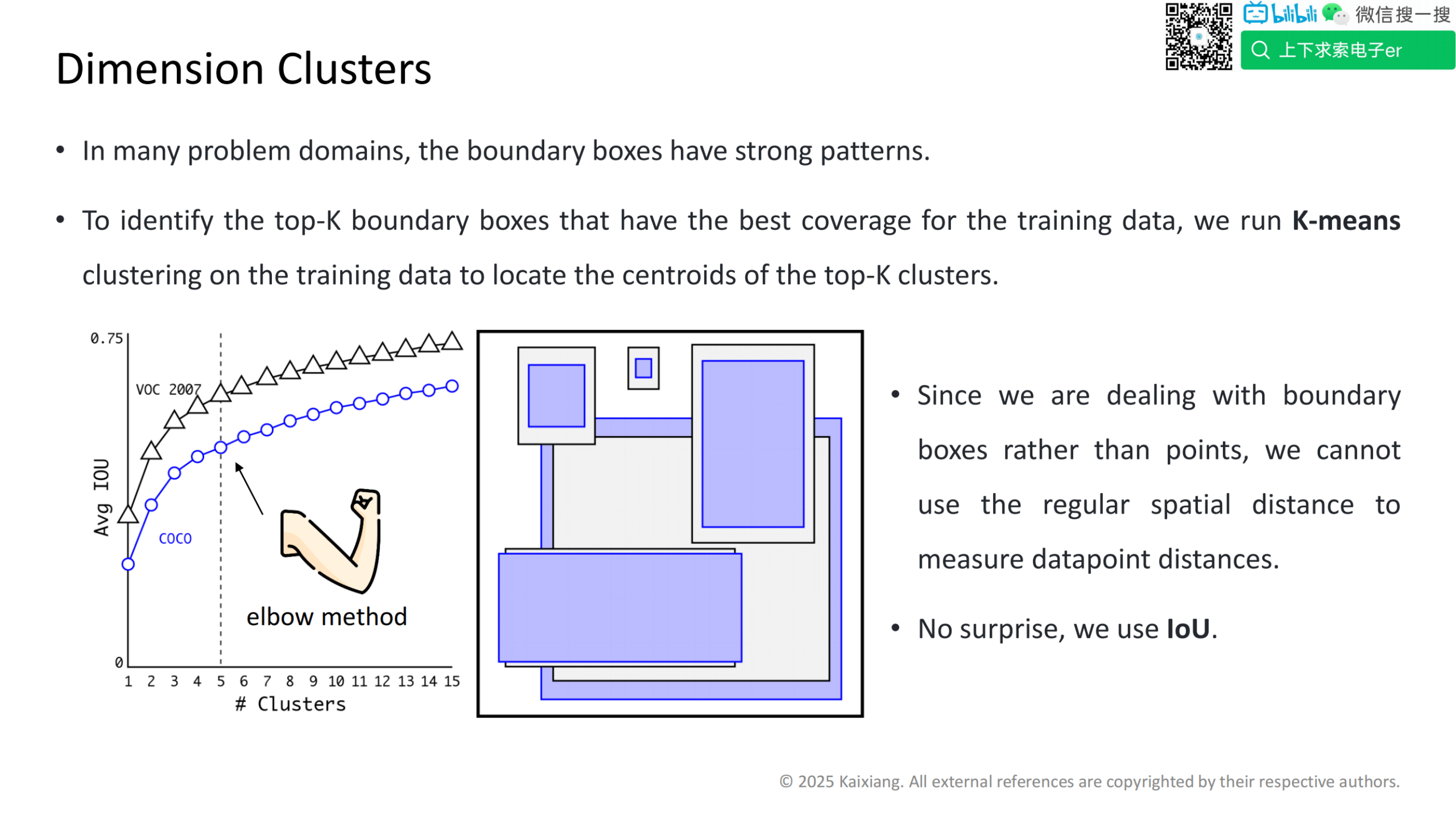
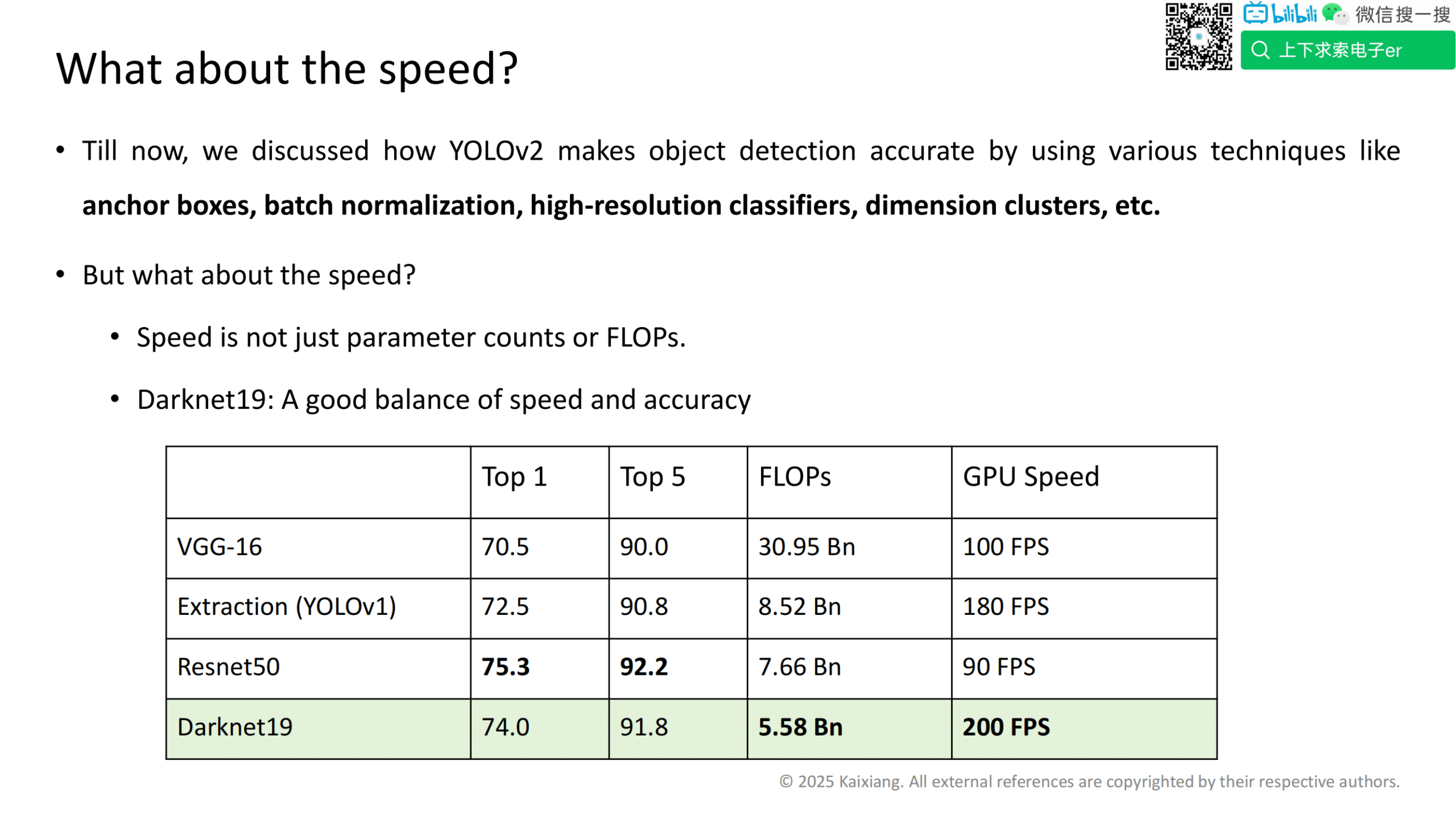
网络结构的改进
突出 Darknet19(骨干网络)的关键特性。
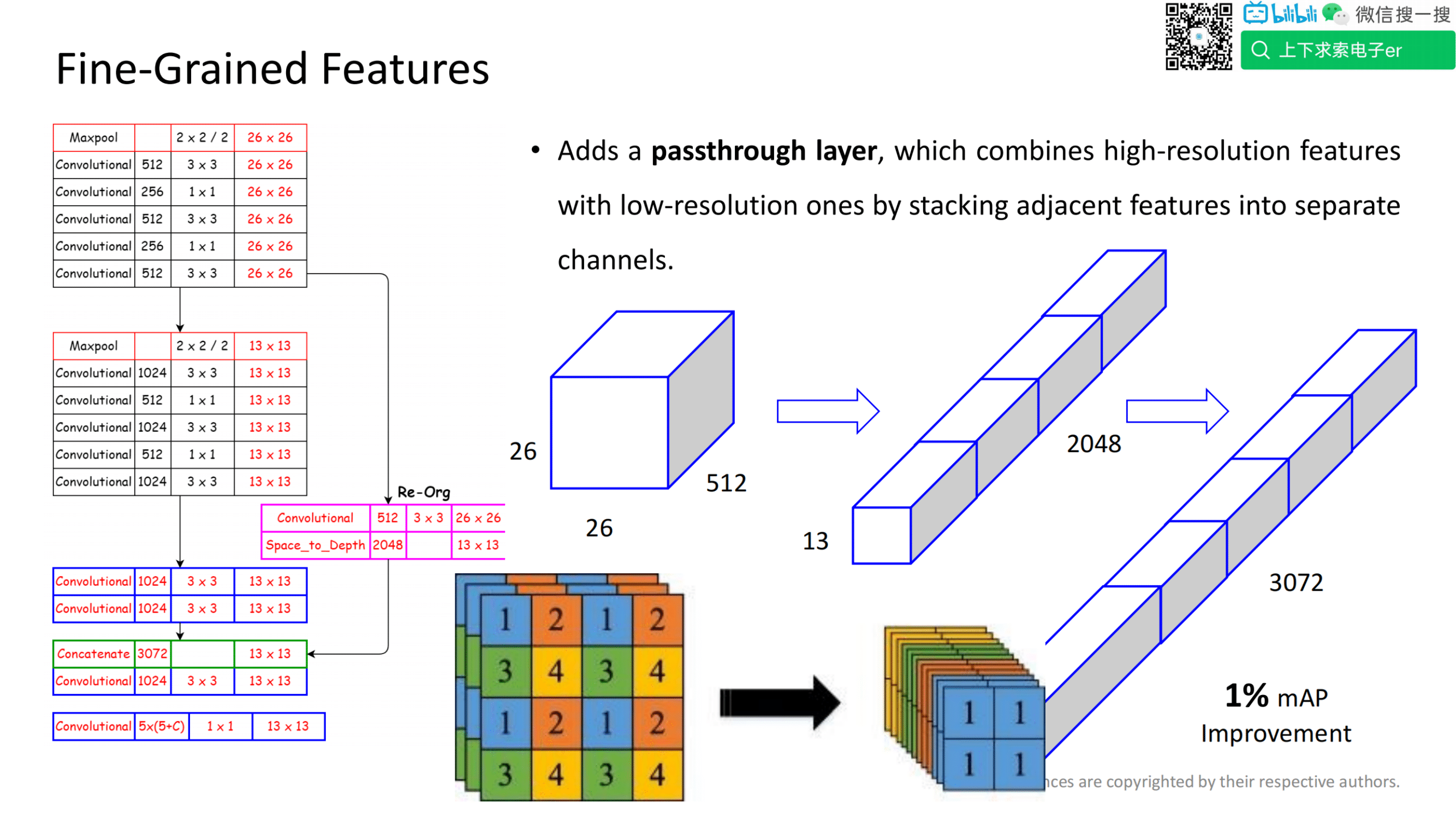
提取细粒度特征,从而实现更好的目标定位和详细的预测。
训练策略的改进。
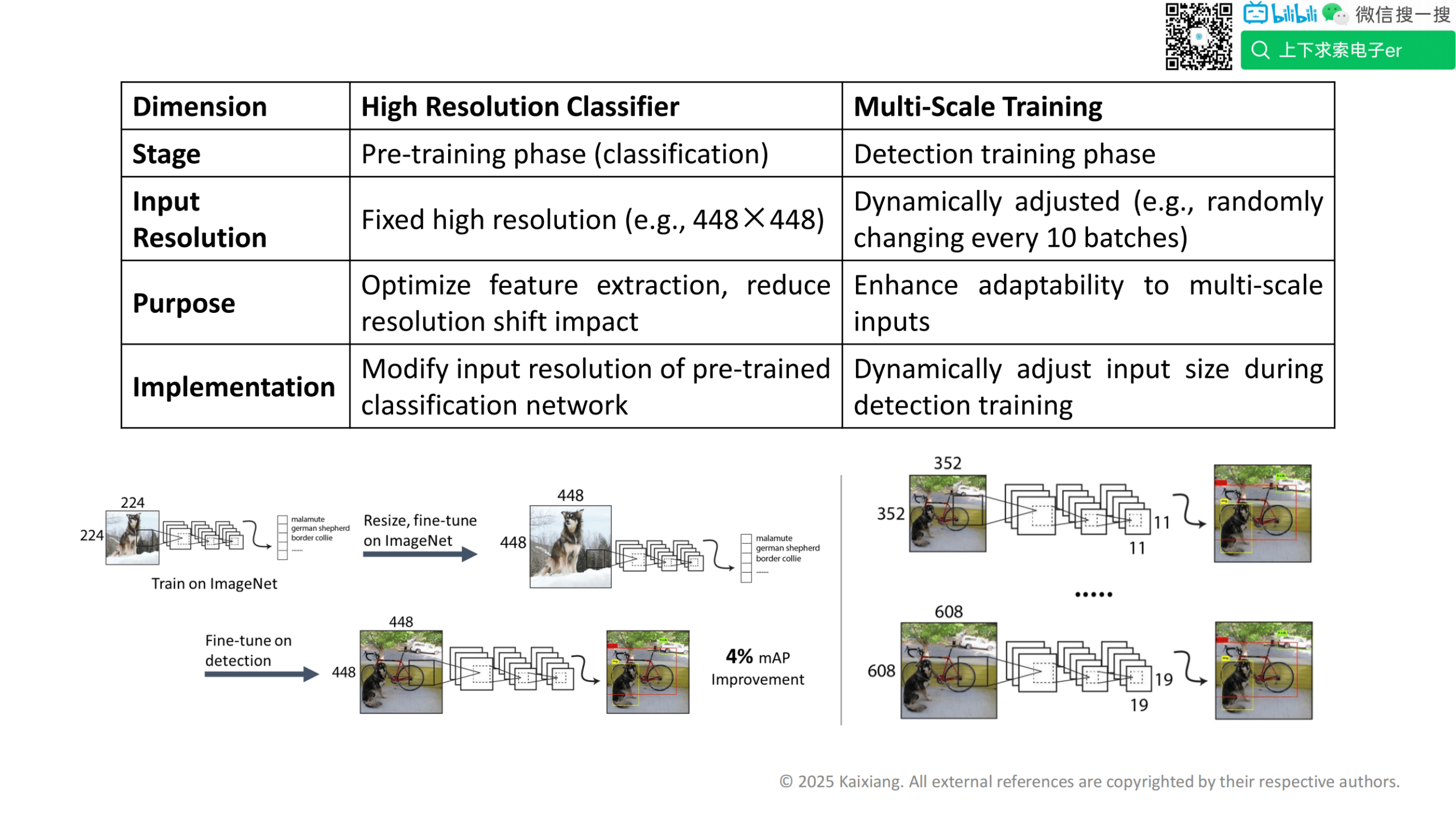
高分辨率分类器
多尺度训练
训练阶段:
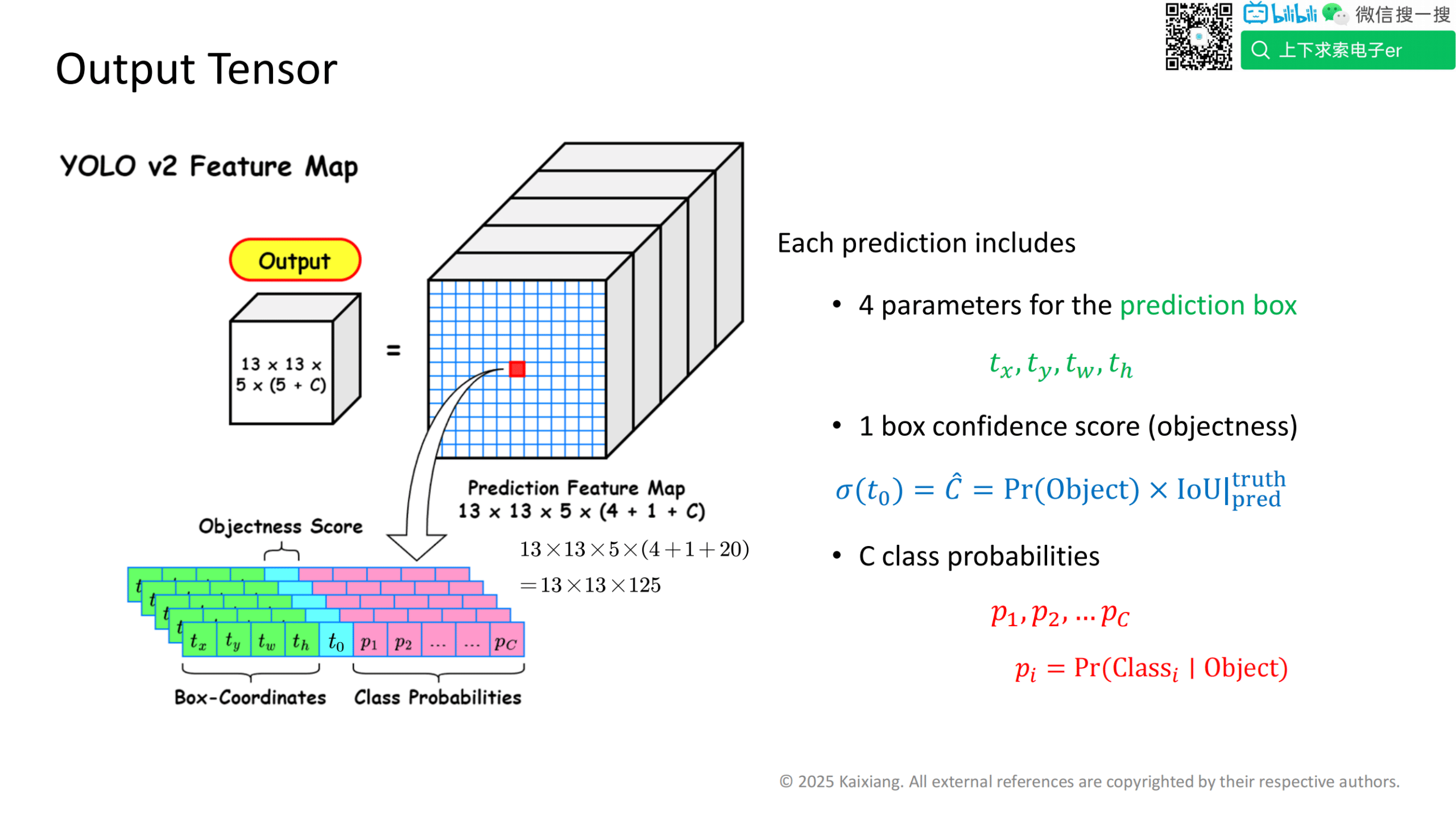
关注输出张量如何与真实标签关联。
测试阶段:
将输出张量转换为最终预测结果。

卷积操作:
3x3 滤波器:提取空间特征,同时保留空间信息。
1x1 滤波器:调整通道维度,减少计算量。
优点:
减少参数,提高效率。
保持足够的感受野。
批归一化(Batch Normalization):
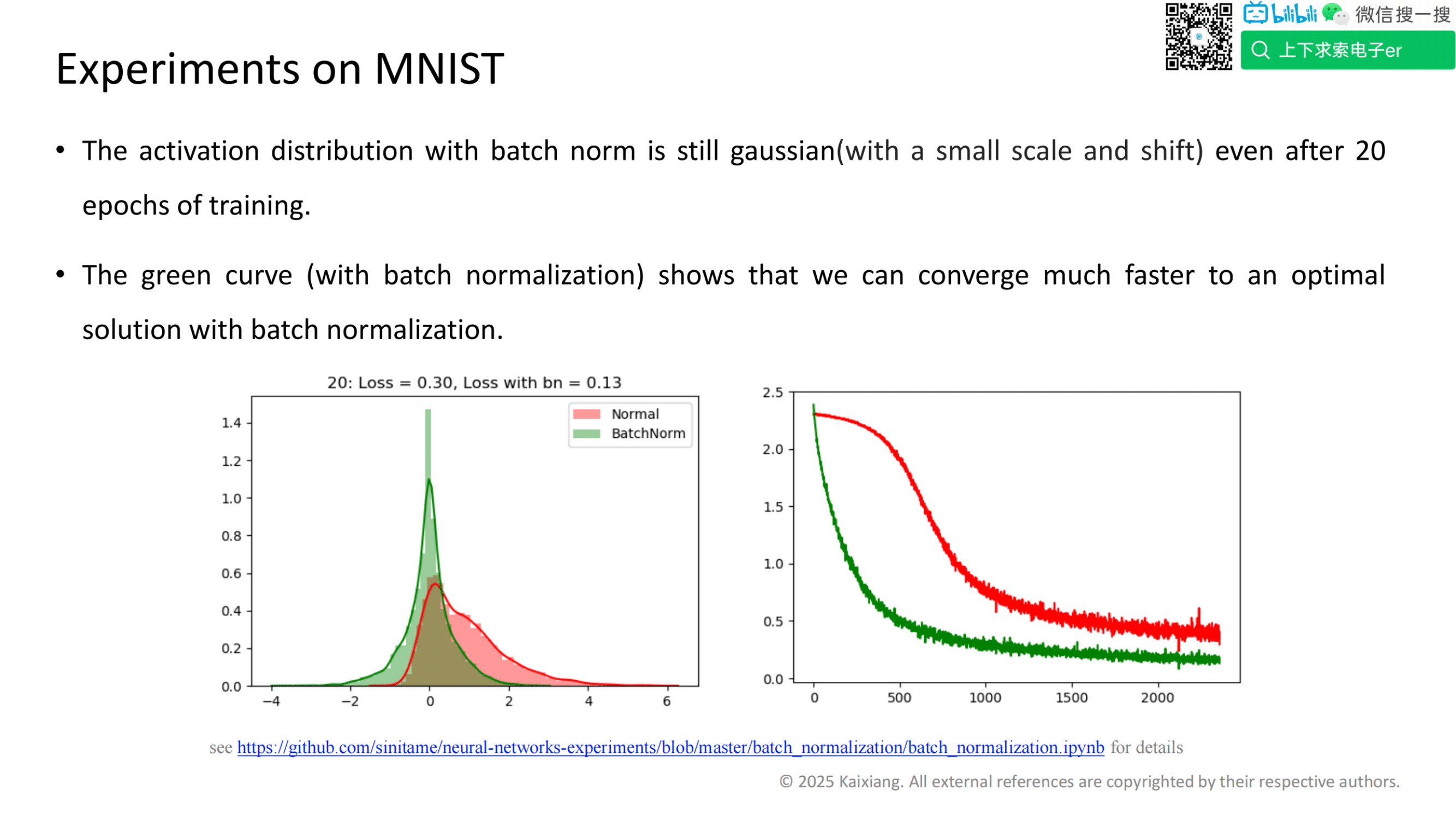
有助于加速模型收敛,并防止梯度消失。提高模型稳定性,在 Darknet19 中,批归一化被用于每个卷积层。
全局平均池化(Global Average Pooling):
在网络的最后阶段,我们把输出的特征图的每一个通道,构成一个值,下图中输出特征图是1000个通道的,我们把每一个通道的值求平均,得到一个值。就得到了1000维度的向量。
将它输出到 softmax层,进行分类,能够大大减少,参数爆炸的问题。
两个 3x3 卷积 = 一个 5x5 卷积
三个 3x3 卷积 = 一个 7x7 卷积

批归一化(Batch Normalization)
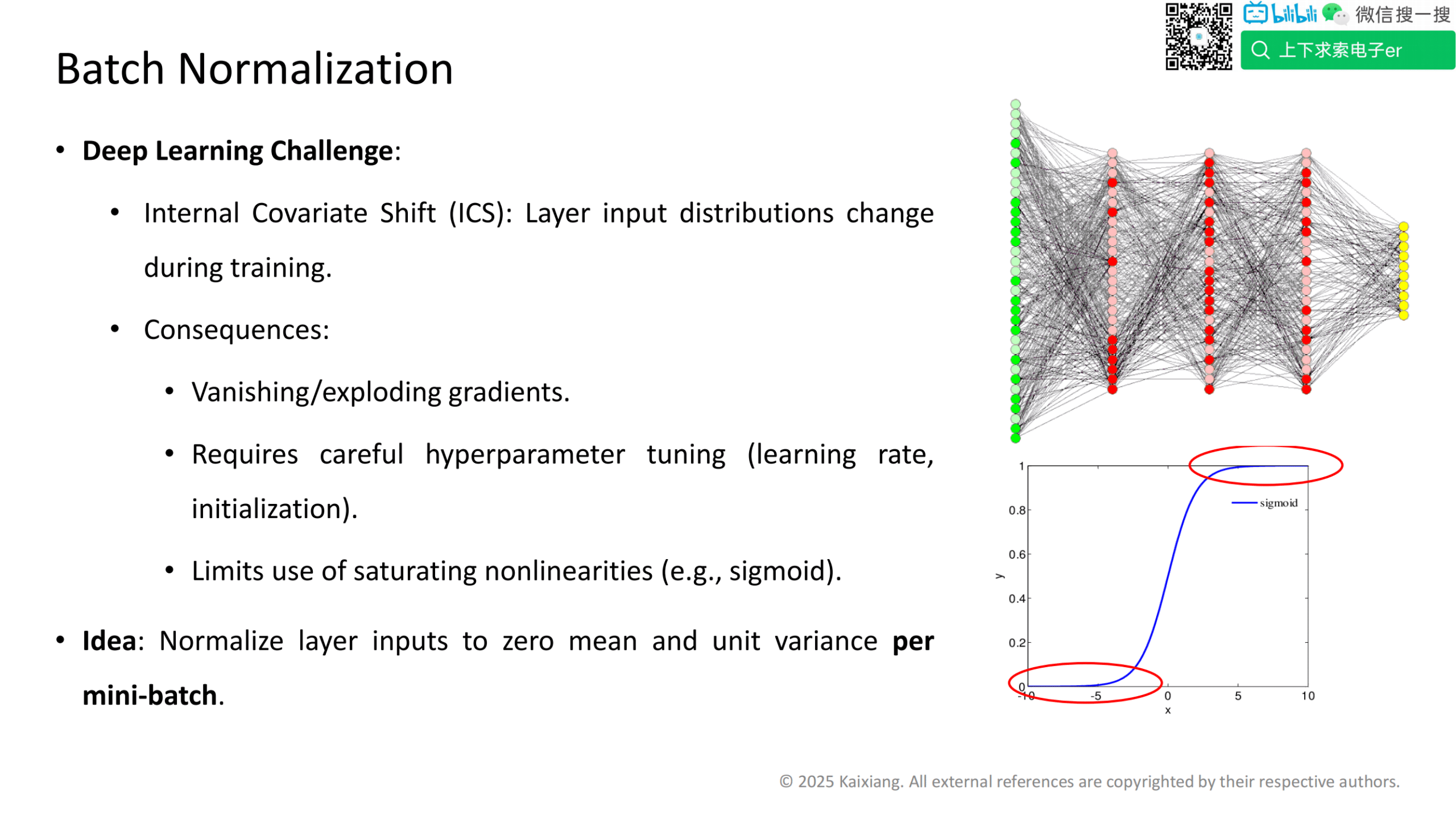
深度学习挑战:
内部协变量偏移(Internal Covariate Shift, ICS):在训练过程中,层输入的分布会发生变化。
后果:
梯度消失或梯度爆炸。
需要仔细调整超参数(例如学习率、初始化)。
限制了饱和非线性激活函数(例如 sigmoid)的使用。
思路:
每个小批量(mini-batch)对层输入进行归一化,使其具有零均值和单位方差。
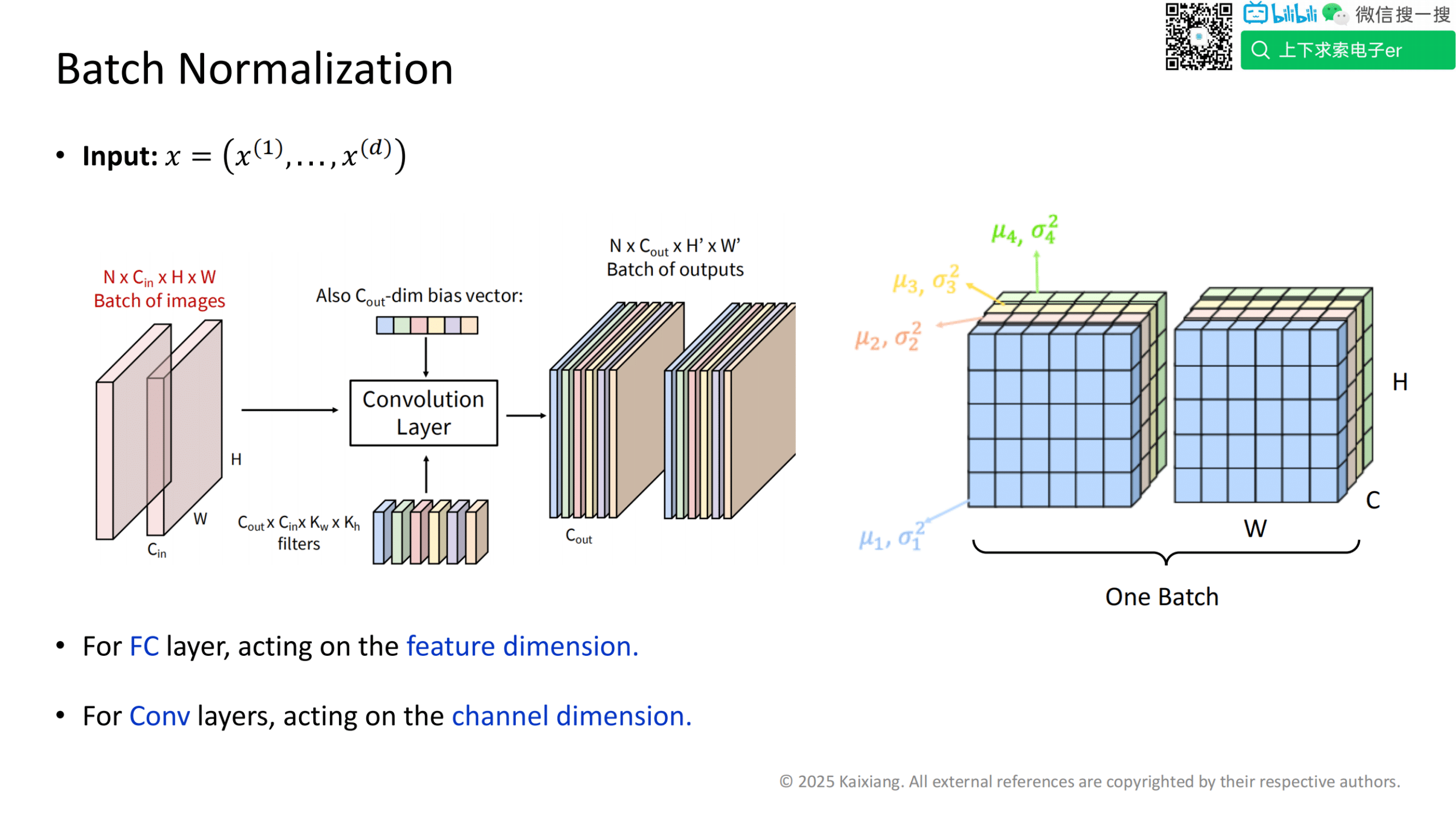
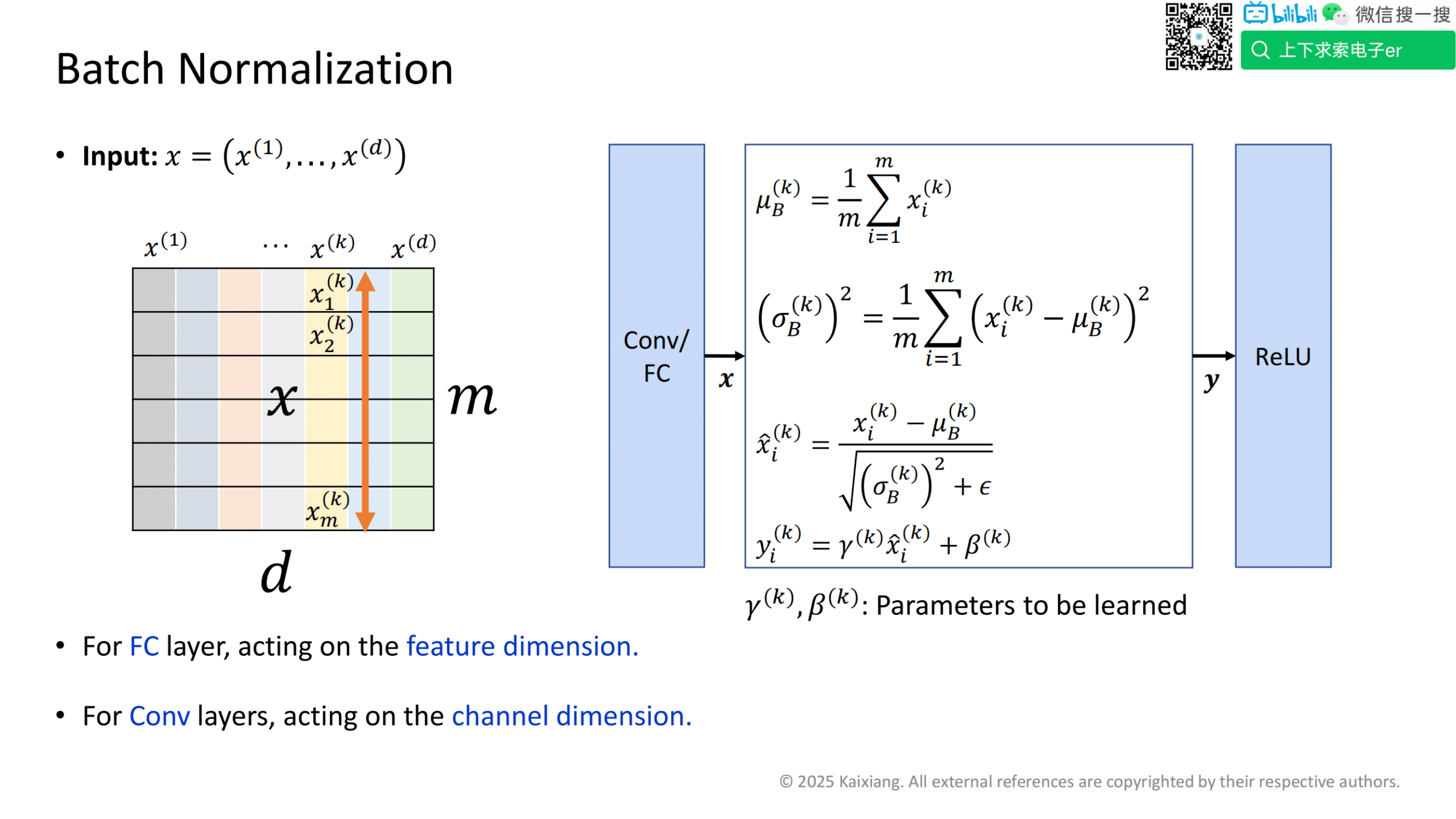
FC (全链接层)
对于输入的小数据量x, 有m个样本组成,每个样本有d个特征,可以理解为 d * m 的矩阵
每一行代表一个样本,每一列代表一个特征
为们要对矩阵中的每一个元素进行归一化,
1、计算每个特征的均值,对于第k个特征,他的计算公式为右侧第一个
我们会将第k个特征的m条样本累加求和,再除以m,得到第k个特征的均值。
2、计算每个特征的方差,对于第k个特征,他的计算公式为右侧第二个
3、对与列上的每一个元素第k个特征的第i个元素,我们就用它原来的值减去第k个特征的均值,再除以标准差 ,来得到更新后的值,,他的计算公式为右侧第二个 E 为小的波动,防止分母为0
4、
Conv (卷积网络)